Policy-in-the-Loop World-Model Evaluation
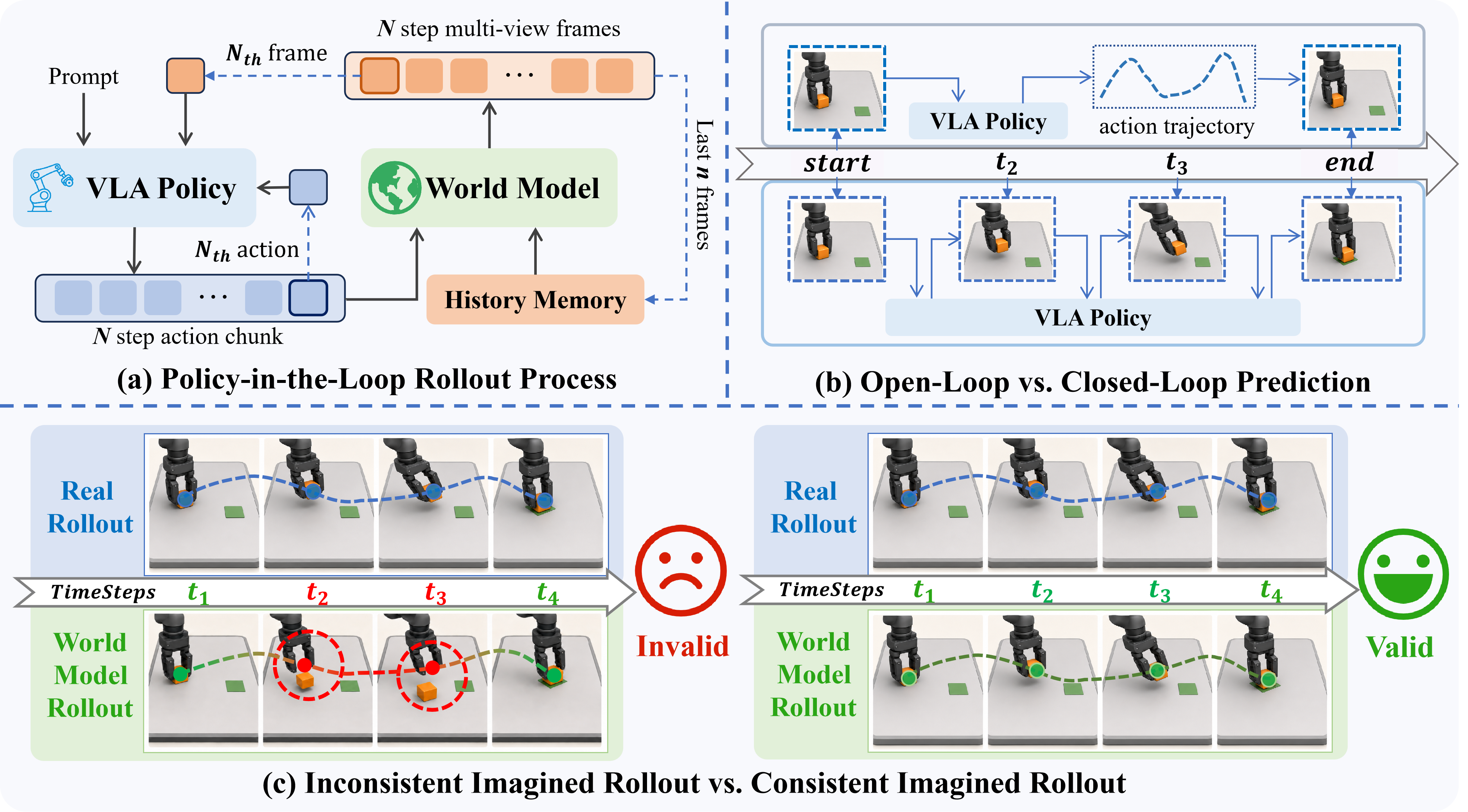
Policy-in-the-loop evaluation requires a world model to map VLA-predicted action chunks to future observations and feed them back for subsequent policy queries. This differs from open-loop prediction, where the action trajectory is pre-collected and fixed. A valid imagined rollout should remain consistent with the real execution process rather than only producing visually plausible frames.
PiL-World Framework
PiL-World first learns general robot-environment dynamics through pretraining on RealSource World, and is then fine-tuned on target-task trajectories containing both successful demonstrations and failed teleoperated executions. During rollout, a frozen VLA policy predicts an action chunk from the current observation and instruction. PiL-World projects this action chunk into visual control signals, conditions generation on latent history memory, and predicts a stride-aligned multi-view future segment. The terminal generated observation is fed back for the next policy query, and the resulting imagined rollout is compared with real-robot execution for evaluation.
Closed-Loop Rollout Results
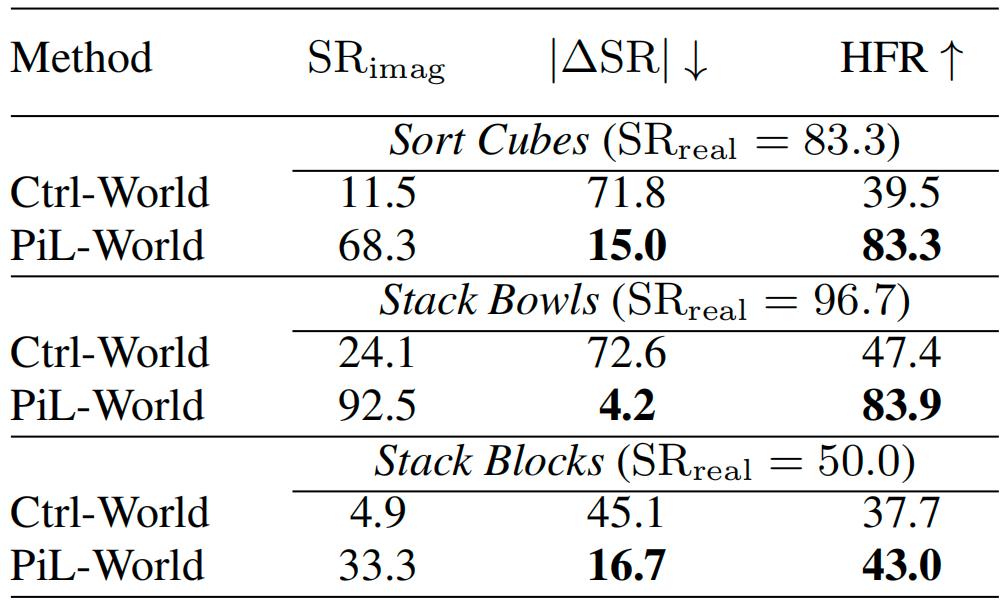
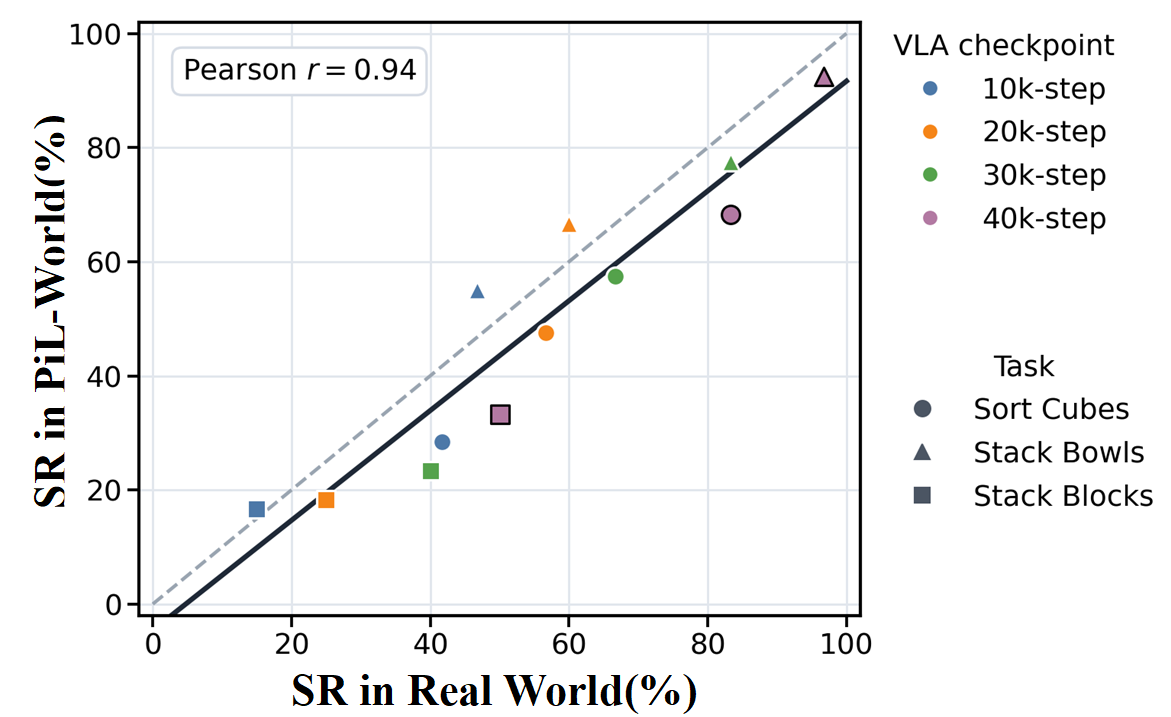
PiL-World is evaluated on three real dual-arm manipulation tasks: sorting cubes, stacking bowls, and stacking blocks. Across the tasks, PiL-World reduces the average real-imagined success-rate gap from 63.2% for Ctrl-World to 12.0%, and improves average hallucination-free ratio from 41.5% to 70.1%. The following video compares real execution, PiL-World imagined rollout, and Ctrl-World imagined rollout.
Single-Step Prediction Results
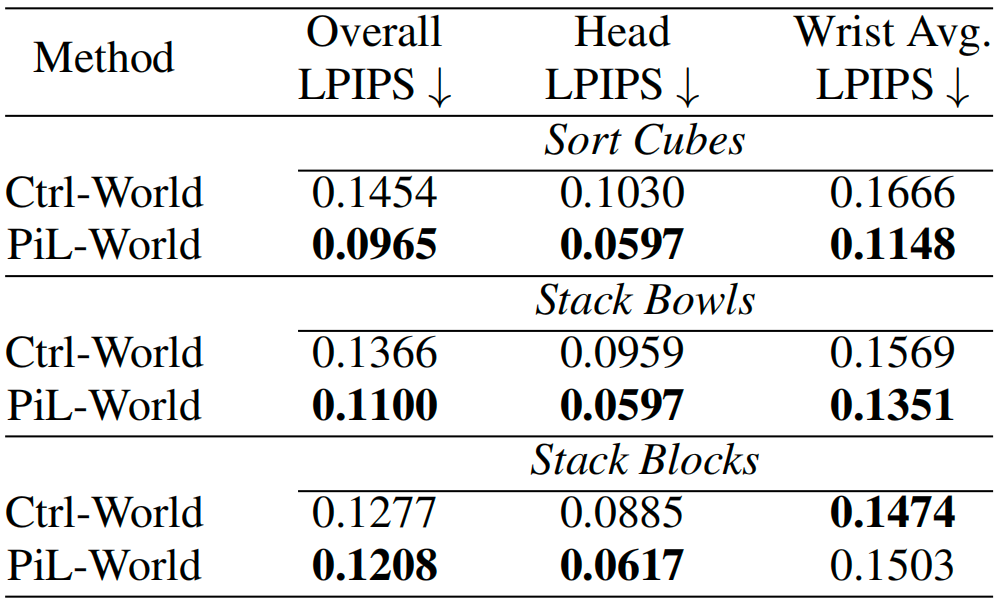
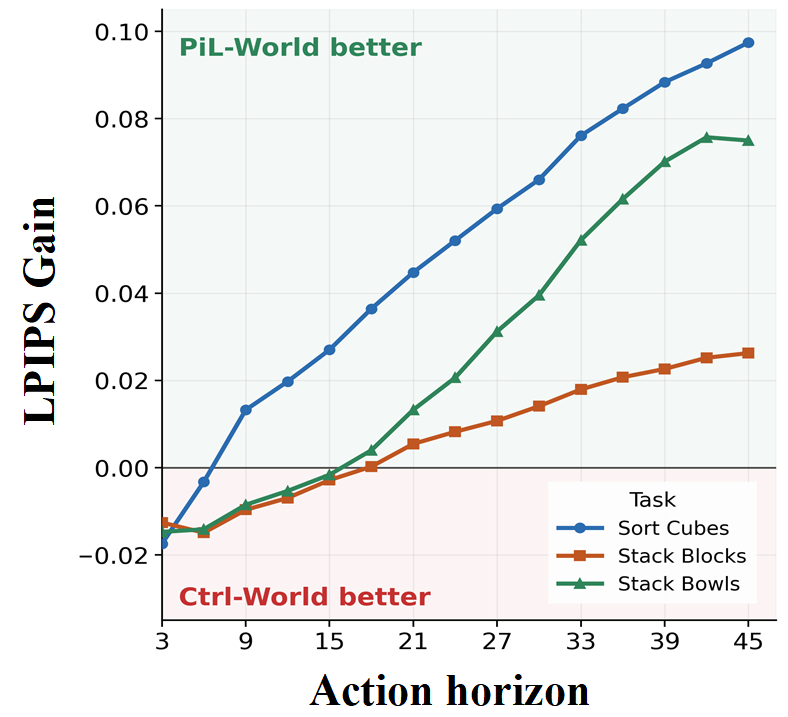
PiL-World also achieves lower single-step LPIPS than Ctrl-World on all three tasks, indicating stronger action-conditioned visual prediction quality. The gain becomes more pronounced at later predicted frames, showing that PiL-World maintains lower perceptual prediction error over longer action-conditioned horizons.